
Oggi Kubernetes è lo standard per l'orchestrazione dei container e viene adottato da un numero crescente di aziende, con modalità differenti, per semplificare i processi operativi e ottimizzare la gestione delle risorse grazie alla sua capacità di automazione, scalabilità e flessibilità.
Questo ha reso necessario la creazione di sistemi che semplificano il deploy delle applicazioni, sostituendo i tradizionali metodi di installazione su macchine virtuali o fisiche con soluzioni più snelle, agili e automatizzate.
Oggi andiamo ad analizzare uno di questi strumenti.
Strimzi è un progetto open source che semplifica il deploy e la gestione di un cluster Apache Kafka su Kubernetes.
Grazie a Strimzi, è possibile gestire in modo efficiente anche utenti, topic, MirrorMaker e Kafka Connect, utilizzando le Custom Resources di Kubernetes. Questo approccio consente una gestione centralizzata e scalabile di Kafka, integrandosi perfettamente con l'ecosistema Kubernetes.
In questo articolo vi mostrerò come eseguire il deploy di un cluster Apache Kafka su Kubernetes utilizzando Strimzi.
Il cluster sarà composto da tre broker con kraft
Inoltre vi mostrerò come esporre il cluster all'esterno.
Prerequisiti
Risorse minime per l'installazione di un cluster Kafka:
1 cluster Kuberentes con:
- 1 nodo Master
- 1 nodo Worker
- Ingress controller per eseposizione dei servizi all'esterno
- Storage Class per la gestione dei persisten volume
- Helm Installato
Conoscenza minima di:
- Kubernetes
- Kafka
Cosa utilizzerò per questa guida?
Per questa guida utilizzerò un cluster Kubernetes con le seguenti caratteristiche:
- 3 nodi Master
- 2 nodi Worker
- Storage class Cinder (Openstack)
- Nginx Ingress controller
- Nome Namespace: kafka
- Nome Cluster: k8s-overflowjournal
Fase 1 - Installazione dell'operatore
Per prima cosa, creiamo il namespace che utilizzeremo in questo tutorial.
Lo chiameremo kafka.
kubectl create namespace kafkaTerminata la creazione del namespace possiamo procedere con l'installazione dell' operatore.
kubectl create -f 'https://strimzi.io/install/latest?namespace=kafka' -n kafkaTerminata l'installazione dovreste trovarvi il primo pod in esecuzione sul namespace Kafka.
Il risultato dovrebbe essere simile a questo:

L’operatore è un componente fondamentale: monitora costantemente le risorse Kubernetes e gestisce l’intero ciclo di vita di un cluster Kafka, occupandosi della creazione, degli aggiornamenti e della rimozione delle sue componenti.
Inoltre, l’operatore gestisce anche risorse applicative come utenti, topic e altri oggetti correlati al cluster Kafka.
Questa gestione avviene tramite le CRDs installate nel cluster durante il deployment dell’operatore.
In Kubernetes, le CRD (CustomResourceDefinition) sono il meccanismo che consente di estendere l’API introducendo nuovi tipi di risorse personalizzate.
L’operatore utilizza quindi queste definizioni per controllare e automatizzare l’intero ciclo di vita del cluster Kafka in modo dichiarativo.
Oggi esistono centinaia di operatori Kubernetes, ampiamente utilizzati per gestire in modo automatico infrastrutture complesse e ad alta affidabilità, a partire da un semplice manifest, come nel caso di Strimzi per Kafka.
Per verificare quali CRDs sono state installate nel cluster, è possibile eseguire il seguente comando.
kubectl get crds | grep strimziIl risultato dovrebbe essere simile a questo:
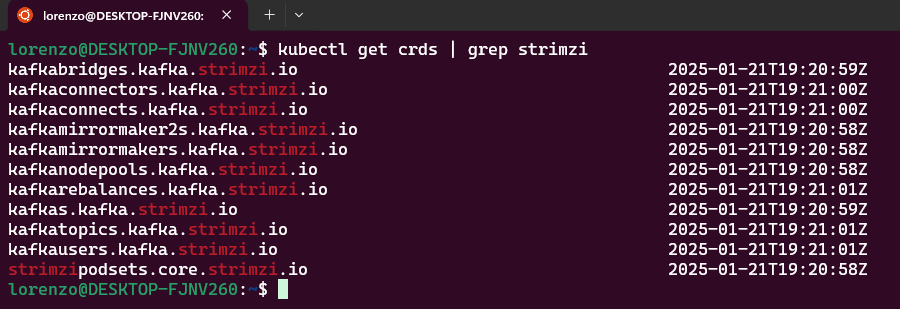
Le CRDs che a noi interessano sono le seguenti:
- kafkas.kafka.strimzi.io
- kafkanodepools.kafka.strimzi.io
Fase 2 - Perparazione del manifest e configurazione del cluster
Di seguito ho preparato un esempio di manifest che andrò ad applicare per creare un cluster Kafka ed andremo ad analizzare insieme le varie opzioni:
apiVersion: kafka.strimzi.io/v1
kind: Kafka
metadata:
name: kafka-overflowjournal
namespace: kafka
annotations:
strimzi.io/node-pools: enabled
strimzi.io/kraft: enabled
spec:
entityOperator:
topicOperator: {}
userOperator: {}
kafka:
authorization:
superUsers:
- kafka-admin
type: simple
config:
default.replication.factor: 3
inter.broker.protocol.version: '3.6'
min.insync.replicas: 2
offsets.topic.replication.factor: 3
transaction.state.log.min.isr: 2
transaction.state.log.replication.factor: 3
jvmOptions:
'-Xms': 2g
'-Xmx': 2g
listeners:
- authentication:
type: scram-sha-512
name: plain
port: 9092
tls: false
type: internal
- authentication:
type: scram-sha-512
configuration:
bootstrap:
host: kafka.overflowjournal.it
brokers:
- broker: 0
host: kafkabroker0.overflowjournal.it
- broker: 1
host: kafkabroker1.overflowjournal.it
- broker: 2
host: kafkabroker2.overflowjournal.it
name: tls
port: 9093
tls: true
type: ingress
---
apiVersion: kafka.strimzi.io/v1
kind: KafkaNodePool
metadata:
name: broker
namespace: kafka
labels:
strimzi.io/cluster: kafka-overflowjournal
spec:
replicas: 3
roles:
- broker
- controller
storage:
type: persistent-claim
size: 50Gi
jvmOptions:
'-Xms': 2g
'-Xmx': 2g
La prima cosa che notiamo sono le annotations.
Queste due righe sono fondamentali nelle versioni moderne di Strimzi:
strimzi.io/node-pools: enabledindica all'operatore che i nodi del cluster sono gestiti tramite una risorsa separata chiamataKafkaNodePool(la vedremo dopo). Senza questa annotation, Strimzi ignorerebbe completamente quella risorsa.strimzi.io/kraft: enabledabilita la modalità KRaft, che è la grande novità degli ultimi anni di Kafka. In passato, Kafka dipendeva da un sistema esterno chiamato ZooKeeper per gestire i metadati del cluster. Con KRaft, Kafka gestisce tutto internamente, senza dipendenze esterne. Questo semplifica enormemente il deployment e migliora le performance.
Autorizzazione
authorization:
superUsers:
- kafka-admin
type: simpleKafka supporta diversi modelli di autorizzazione.
Nell'esempio uso simple, che si basa sulle ACL (Access Control List) native di Kafka.
Ogni utente può avere permessi specifici su topic, consumer group e cluster.
I superUsers sono utenti speciali che hanno accesso completo senza bisogno di ACL specifiche.
In questo caso, l'utente kafka-admin è l'amministratore del cluster.
In questo esempio ho creato solo un utente di tipo "superUsers"
In un ambiente di produzione è consigliato creare ulteriori utenti e relativi permessi.
Approfondirò questa tematica in un articolo futuro.
Configurazione del cluster
config:
default.replication.factor: 3
min.insync.replicas: 2
offsets.topic.replication.factor: 3
transaction.state.log.min.isr: 2
transaction.state.log.replication.factor: 3
Questi parametri controllano la durabilità dei dati.
Per capirli bisogna sapere come funziona la replica in Kafka:
ogni topic è diviso in partizioni, ed ogni partizione è replicata su più broker.
Il broker che "guida" una partizione si chiama leader, gli altri sono follower.
default.replication.factor: 3significa che ogni partizione viene replicata su tutti e 3 i broker. Se un broker muore, i dati sono ancora disponibili sugli altri due.min.insync.replicas: 2è il parametro di sicurezza critico: Kafka considera una scrittura come "confermata" solo quando almeno 2 broker su 3 l'hanno ricevuta. Questo garantisce che anche se un broker muore subito dopo una scrittura, i dati non vengono persi.
Con questo valore il cluster tollera la perdita di 1 broker senza perdita di dati.- Le ultime tre righe applicano gli stessi principi ai topic interni di Kafka:
__consumer_offsets(che memorizza la posizione di lettura di ogni consumer) e__transaction_state(che gestisce le transazioni).
I Listener
listeners:
- name: plain
port: 9092
type: internal
tls: false
authentication:
type: scram-sha-512
- name: tls
port: 9093
type: ingress
tls: true
authentication:
type: scram-sha-512
configuration:
ingressClassName: nginx
bootstrap:
host: kafka.overflowjournal.it
brokers:
- broker: 0
host: kafkabroker0.overflowjournal.it
- broker: 1
host: kafkabroker1.overflowjournal.it
- broker: 2
host: kafkabroker2.overflowjournal.it
I listener sono i "punti di accesso" al cluster Kafka.
In questo esempio ho configurato due listener con scopi diversi.
Il primo, chiamato plain, è per i client interni al cluster Kubernetes, ad esempio può essere utilizzato per i migro servizi che girano all'interno del cluster.
Non usa TLS perché il traffico rimane sulla rete privata di Kubernetes, ma richiede comunque autenticazione tramite SCRAM-SHA-512: un meccanismo challenge-response in cui la password non viaggia mai in chiaro sulla rete (a differenza del meccanismo PLAIN).
Il secondo, chiamato tls, è per i client esterni al cluster, raggiungibile da internet.
Usa il tipo ingress, che fa sì che Strimzi crei automaticamente degli oggetti Ingress Kubernetes per esporre i broker verso l'esterno.
Qui ovviamente il TLS è obbligatorio.

Una cosa interessante di Kafka è che il protocollo richiede connessioni dirette ai singoli broker: non puoi mettere un semplice load balancer davanti.
Per questo ogni broker ha un hostname dedicato (kafkabroker0, kafkabroker1, kafkabroker2).
Il bootstrap è invece il punto di ingresso iniziale: il client si connette lì per ottenere la lista dei broker, poi si connette direttamente a ciascuno di essi.
Strimzi supporta diverse combinazioni di "accesso".
La configurazione proposta in questo esempio è quella più comune (plain per i servizi interni al cluster e TLS per i servizi esterni al cluster).
Tuttavia nulla vieta di far comunicare in TLS anche i servizi interni.
Ci sono numerose combinazioni e l'utente può scegliere a piacimento le configurazioni in base alle sue esigenze.
I Nodi del cluster
apiVersion: kafka.strimzi.io/v1
kind: KafkaNodePool
metadata:
name: broker
namespace: kafka
labels:
strimzi.io/cluster: kafka-overflowjournal
spec:
replicas: 3
roles:
- broker
- controller
storage:
type: persistent-claim
size: 50Gi
storageClass: <nome-storageclass>
jvmOptions:
'-Xms': 8g
'-Xmx': 8g
l KafkaNodePool descrive il gruppo di nodi che compongono il cluster. La label strimzi.io/cluster: kafka-overflowjournal è il collegamento tra questa risorsa e il CR Kafka visto sopra.
I ruoli sono la novità di KRaft. In passato, ZooKeeper gestiva i metadati del cluster (chi è il leader, quali partizioni esistono, ecc.).
Con KRaft, questo compito viene svolto da nodi Kafka con ruolo controller.
I nodi con ruolo broker gestiscono invece i dati veri e propri.
In questo setup ho deciso di utilizzare il dual-role: ogni nodo fa entrambe le cose. È la scelta ideale per cluster di piccole-medie dimensioni.
Per cluster molto grandi si preferisce separare i due ruoli.
Lo storage persistent-claim crea un PersistentVolumeClaim Kubernetes per ogni broker: i dati sopravvivono ai riavvii e ai reschedule dei Pod. L'alternativa ephemeral perde tutti i dati al riavvio ed è adatta solo per ambienti di test o demo.
Le JVM options con -Xms e -Xmx uguali (entrambi 2g) fissano la dimensione dell'heap Java a un valore costante, evitando il resize dinamico che causa pause del garbage collector.
Fase 3 - Applicazione del manifest
Una volta definito il manifest con le configurazioni desiderate, possiamo applicarlo al cluster.
- Ingress
- Persistent Storage
Inoltre è buona norma, prima dell'applicazione del manifest, verificare che i record DNS, utilizzati per la connessioni verso i broker Kafka, siano risolvibili.
Nel mio caso i record DNS sono i seguenti.
- kafka.overflowjournal.it
- kafkabroker1.overflowjournal.it
- kafkabroker2.overflowjournal.it
- kafkabroker3.overflowjournal.it
Questi record DNS sono definiti nel manifest e devono poter essere risolti dall'operatore.
Effettuate le verifiche preliminari possiamo finalmente applicare il manifest:
kubectl apply -f kafka.yamlTerminata l'installazione si dovrebbe ottenere un risultato simile al seguente:
Tre pod broker/kraft:
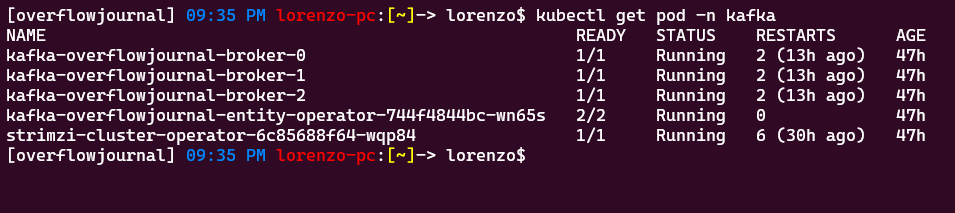
E le relative Ingress per le connessioni esterne:

Inoltre dovremmo avere anche dei Persistent Volume, uno per ogni nodo broker:

Ed ecco il nostro cluster Kafka pienamente operativo in pochi semplici passaggi.
Ovviamente Strimzi, essendo un operatore, può gestire simultaneamente diversi cluster Kafka, in diversi namespace.
Possiamo anche ottenere informazioni sullo stato del cluster interrogando la CR (Custom Resource) creata dal nostro manifest:

Come potete vedere c'è un warining attivo.
Per verificare il messaggio di warining eseguire il seguente comando:
kubectl get kafka kafka-overflowjournal -n kafka -o yamlVerrà mostrata l'intera risorsa creata poco fa ed in fondo il relativo stato.
In questo caso il mio errore è il seguente:
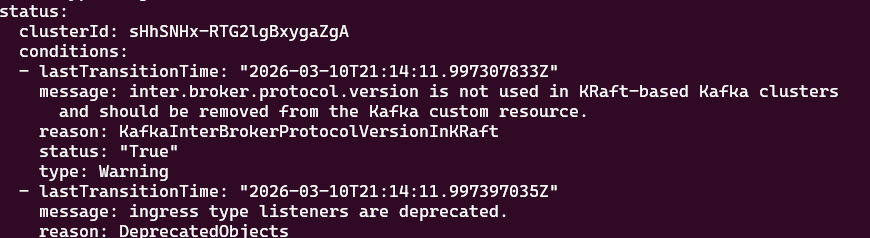
In questo caso, lo stato mi dice che ho lasciato nella configurazione un parametro deprecato: inter.broker.protocol.version is not user in KRaft-based Kafka clusters
Quindi andiamo a risolvere il warning eliminando tale parametro.
Per aggiornare/modificare il manifest eseguire il seguente comando:
kubectl edit kafka kafka-overflowjournal -n kafkaCome potete vedere, una volta modificata la configurazione l'operatore effettuerà un rolling restart dei pod brocker, evitando cosi di dare disservizio

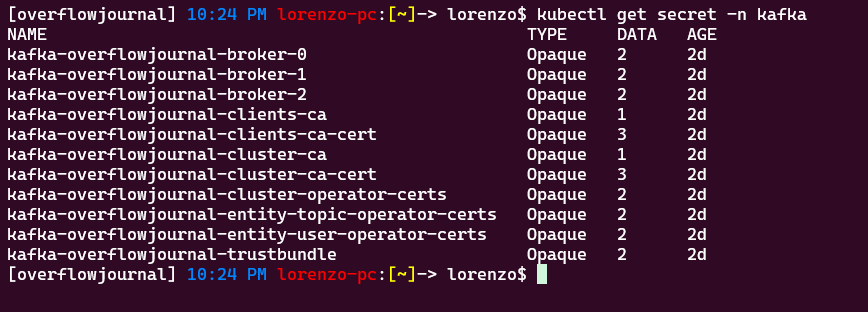
Come ultima cosa, le credenziali di accesso al cluster e i relativi certificati sono stati generati automaticamente dall'operatore e salvate in dei secret
Conclusioni
In definitiva, Strimzi porta Kafka dentro il modello operativo di Kubernetes in modo naturale e ordinato.
Invece di gestire manualmente ogni componente, basta descrivere ciò che si vuole ottenere in un manifest e lasciare che l’operatore si occupi del resto.
Oltre che gestire il ciclo di vita di un cluster kafka, Strimzi può creare/gestire anche componenti come topic e utenti, oggetti presenti all'interno di Kafka.
Approfondirò tali argomenti in dei post successivi.
Vi ringrazio per aver letto fino in fondo questa guida!
Per qualunque domanda potete scrivermi a [email protected]